
遇到的问题
图片文件进行上传时,用户手动将文件的扩展名,比如说,从 .png 修改成 .jpg,使用 input[type="file"] 的 onchange 事件得到的 e.target.files[0].type 会是 image/jpg。
问题显而易见:通过前端手段,如何才能获取文件真实的 MIME TYPE?在这里结果应该是 image/png 才对。
这是我最近一周在项目中面对的问题。自此,有了这篇笔记,这问题的答案也就理所当然的是肯定可以。
解决思路和演示 demo
原理
不复杂,可以概括成一句:使用不同类型文件本身独一无二的签名 file signatures 1,来对文件类型(MIME TYPE)进行匹配,得到结果。
步骤
- 在
input[type="file"].onchange回调事件中,调用FileReader()的readAsArrayBuffer()方法,将获取到的文件转换成ArrayBuffer; - 使用
Typed Array或者DataView将ArrayBuffer转化成可以查看、操作的对象2 ; - 查询相关文件类型签名,从 List of file signatures 和 All File Signatures. 搜索我们需要的签名(比如 JPG/JPEG,可能会是
FFD8FFE0,FFD8FFE1,FFD8FFE2等); - 从第 2 步中得到的对象中提取我们需要的部分,与第 3 步中得到的文件签名进行匹配,得到结果。
比如:假设需要对比一个图像文件是否是 JPG/JPEG 的文件,略过一系列事件监听声明,对比文件类型的操作集中于下:
演示 demo
See the Pen Read File MIME Type using JavaScript by Lien (@movii) on CodePen.
解决问题过程中值得记录的坑
关于 FileReader 的 readAsArrayBuffer() 方法
该方法是用来获取文件的二进制数据,如果搜索到一些相对久远之前的博客内容,可能还会提到一个方法:readAsBinaryString(),虽然不少浏览器中仍旧可以成功调用,不过已经基本被废弃3。
FF D8 FF E1 是什么?
首先,它是四组十六进制数,每一组两位,即 FF D8 FF E0。计算机里由二进制 0 和 1 表示的数据的另外一种展现形式。在这里也是 4 个 byte,每个 byte 由八个 bit 组成。更直观的二进制数 0 和 1 的表示如下:
其次,它是 JPE/JPEG 文件的开头一部分的固定字节。FF D8 FF E1 并不是固定字节,只有 FF D8 是 JPE/JPEG 开头固定的,即 SOI (start of image),接下来有可能是 FF E1(APP1),也有可能是 FF E0(APP0)。
See the Pen Get binary/hex representation of an image by Lien (@movii) on CodePen.
截图:
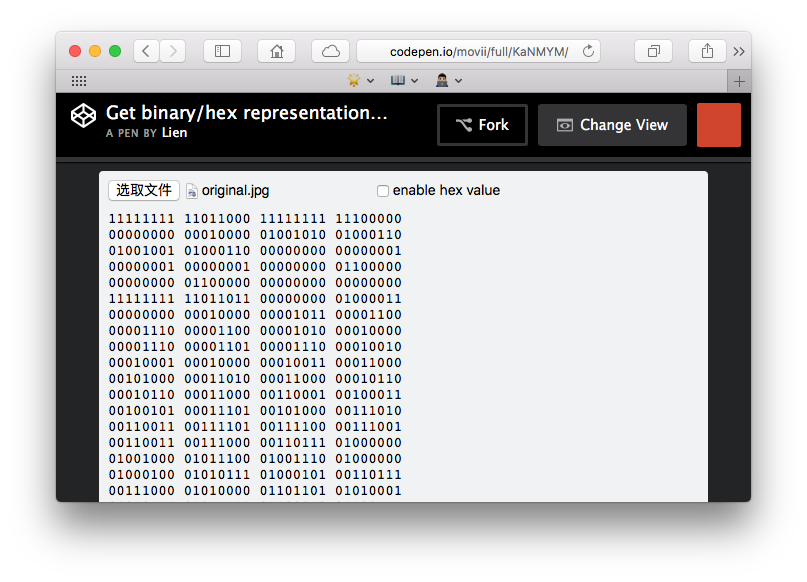
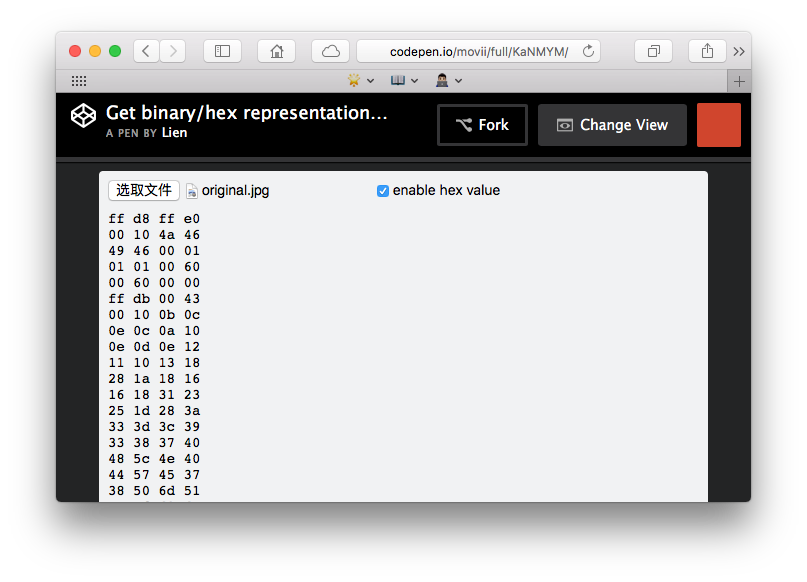
Typed Array v.s DataView ?
解决办法里提到,操作文件二进制数据,JavaScript 提供了 Typed Array 和 DataView 两个 API。但在实际中用中选择使用了 DataView 来处理,因为 Typed Array 来读取 ArrayBuffer 数据时候有两个坑需要面对:
- 字节对齐;
- 字节序。
Typed Array 的字节对齐问题
首先说一下字节对齐,举个例子:
如果将以上 FR.onloadend() 方法内容替换成转换将 ArrayBuffer 包装成 Uint16Array,就会报错:
解释一下:
File类直接继承于Blob类,所以FileReader的方法也可以作用于Blob的实例,所以首先构造了一个strBlob,然后通过FileReader的readAsArrayBuffer()来获取我们想要用来构造Typed Array的ArrayBuffer。- 第一步构造的是
Uint8Array,Uint8Array中的每一个元素就是一个八位无符号整数,比如说str中的a这个字母,就被转换成了97,对应的八位无符号整数就是01100001,实际上就是由八个 bit 组成的一个 byte。 - 替换
FR.onloadend()方法内容后,将arrayBuffer转换成Uint16Array,发生了什么以至于报错?做了两个对比,对照帮助理解:
Uint16Array 中的每个元素都是 2-bytes-wide 的长度,即十六位无符号整数,我们处理的字符串是 abcde,每个字母对应一个八位整数,所以 Uint16Array 最后一个元素就缺少了一位。
Typed Array 的字节序列问题
接着是字节序,先来复现一下遇到的坑:
首先假设我们拿到了一张 .jpg 文件的 ArrayBuffer:
通过 Uint8Array 来构造数据并查看文件头信息,得到的结果:ffd0ffe8,没问题:
接着看 Uint16Array,输出 d8ffe0ff :
最后 Uint32Array,得到的结果:e0ffd8ff:
Uint8Array 构造输出的完全没问题,因为数组里一个无符号整数元素正好对应一个八 bit 的字节,但是 Uint16Array 和 Uint3Array 都分别出现乱序,因为前者一个元素代表了两个字节,而后者一个元素代表了四个字节。那么为什么多于一个字节就会出现乱序?这就是字节序问题(Endian)。
这个字节序问题到底是什么?
从 《TypedArray or DataView: Understanding byte order》引用一句:
the order of bytes in a value that is longer than one byte differs depending on the endianness of the system.
往长了说,可以参考维基百科:EN,ZH 和这篇 《Binary World:ArrayBuffer、Blob以及他们的应用》;短一点的解释则是,不同国家的人使用不同的语言以及语言书写方式,有从左往右,也有从右往左,计算机业和它的语言也是一样,对于数据(字节 byte)的存储有小端序(little-endian)、大端序(big-endian)等之分。
其实到了这里,在制作 demo 的过程中仍旧不能十分确定 Uint16Array 和 Uint32Array 乱序是因为大小端序问题,直到找到了 DataView,并对其进行了验证。
DataView
JavaScript 针对二进制数据处理不仅提供了以上 Typed Array,同时还提供了一个 DataView,主要的区别在于 DataView 本身的方法可以直接避免遇到以上的坑。比如:
以下写了一个非常简单的例子,结合了 Typed Array 和 DataView 以及遇到的 FFD8FFE0,想要验证以上的 Uint32Array 问题确实是由于浏览器的字节序引起:
这里做了什么?
- 这里首先新建了一个四个字节长度的空
ArrayBuffer,首先用Uint8Array作为 view 对它进行操作,依次写入四个字节:0xFF、0xD8、0xFF、0xE0。 - 接着使用 DataView 对已经被修改了的
ArrayBuffer进行读取。
之所以介绍并且使用 DataView.getUint32() 这个方法来做验证,是为了对应上文中 Uint32Array 出现的乱序。强调一下 DataView 还有 getUint8()、getUint16() 等方法,对应到 Uint8Array 和 Uint16Array 等的验证,可以自己参考 MDN 相关文档 DataView 尝试一下)。
从输出的结果来看,当指定为 isLittleEndian 为 true 的时候,即以小端序的方式获取数据,得到的结果和上文中 Uint32Array 获取到的数值一致:e0ffd8ff。结合 checkEndian() 方法得到的结果,浏览器环境中默认确实是以小端序存储、读取数据,而遇到的 Typed Array 的字节乱序问题也确实是由于这个引起。同时也可以得出结论,虽然 wiki 上有,JEP/JEPG 文件是以 big-endian 方式进行数据(byte)写入。
而在 demo 中使用 DataView 作为 ArrayBuffer 的 view 来对其进行读取操作正是因为以上这个原因。
MIME TYPE sniffing
我的笔记标题是《使用 JavaScript 识别文件 MIME TYPE 类型》,但我在 demo 中所做的虽然可以在一定程度上检测出图片是否是 JPEG 格式,可实际上并不是非常严谨的处理方式。这里贴一下 MIME Sniffing Standard 作为更严谨验证 MIME TYPE 的参考。
后续问题和值得记录
通过裁切文件获得文件头部分
在原来的问题解决办法中,读取文件二进制内容到检测文件类型的步骤:input 拿到 file后,通过 readAsArrayBuffer() 方法对二进制数据进行包装,从而进行文件类型的检测。
如果在这里对文件类型的检测是后续文件上传操作的前奏,那么检测本身并不需要提取全部文件内容,有以下几个原因:
- 文件头,比如 JEPG,只需要针对开始的四个字节进行比对是否是
FF D8 FF E1之类;别的文件头验证也不会很长,这时不需要文件的全部二进制内容; - 上传数据接口可能是二进制直接上传,也有可能会通过
canvas剪裁之后转换成 base64 的格式,这时也不需要文件的全部二进制数据内容; - 文件通过检测可能不合法,那么之后不管是可能有的剪裁或者上传操作都会终端取消,所以为什么会需要文件的全部二进制内容 ???
所以针对文件类型的验证只需要文件头部那一段非常短的二进制数据,原来全部读取并不妥善,特别是实操中遇到的文件尺寸比较大的,会有卡顿现象。
优化主要依靠 Blob 类下的 slice() 方法,前文也提到,File 类直接继承于 Blob 类,所以 File 本身也可以使用 slice() 方法对其自身进行裁切,提取开头的一小部分出来。
Blob.slice() 本身的使用方法不做展开,直接上伪代码:
值得学习的 Buffer to String
这一部分并不是解决或者优化什么问题,只是 some how worth noting。针对是上一篇中叙述 「FF D8 FF E1 是什么?」的地方,有一个 CodePen 用来展示文件转换成二进制内容的 demo。
最近在翻 Github 的时候非常偶然看到了一个库:tapjs/buffer-to-string ,如其名,不过是将 Nodejs 中的 Buffer 转换成 hex 值的展示。index.js 中的代码并不长,一共只有十八行,非常值得学习。
See the Pen Get binary/hex representation of an image by Lien (@movii) on CodePen.
Buffer to String
结语
抛开 AJAX.send(binary) 之外,这是第一次接触前端在浏览器环境里处理二进制数据,尽可能从头到位写了遍过程,以及处理问题遇到的坑,特别是字节对齐、字节序那一块,希望多多少少对搜索到这文章的人有所帮助。
评论区关于前端检查文件类型的有无必要,at least 我觉得在移动端盛行的今天,如果在前台就可以检查出文件类型问题,则可以直接避免上传到服务器的带宽、流量浪费。但是这篇笔记的处发点:一是在于对一个势在必行的需求的处理过程的总结,希望可以自我梳理一遍涉及到的知识点,分享出来 for anyone’s future reference;二是我并不是 CS 专业,笔记中很多内容除了阅读参考文档、别人的 blog 文章,以及自己做测试之外,并没有更多的依据,所以并不自信每一行每个词都用的正确无误,所以写出来希望了解这块处理的人如果看到任何错误的地方可以加以指正。
参考
- JS中的二进制操作简介
- 位运算
- C++中数据类型字节数和机器字长关系 - dkxsj - 博客园
- Endian的由来 - Digest Net
- C语言中的高位字节和低位字节是什么意思?_C语言中文网
- TypedArray or DataView: Understanding byte order
- The little-endian web?
- How to check file MIME type with javascript before upload?
- how to convert arraybuffer to string
- Javascript Typed Arrays and Endianness
- Byte Order - Big and Little Endian
- Endianness: Big and Little Endian Byte Order
- Big and Little Endian
- Understanding Big and Little Endian Byte Order
- Hexadecimal
使用的在线工具
文件签名(File Signatures)也被称为 Magic Number。 ↩︎
MDN 上的对应文档链接:Typed Array 和 DataView ↩︎
readAsBinaryString()方法被废弃的文章《the readAsBinaryString(blob) method should be considered deprecated》和 MDN 上相关的文档 ↩︎
技术发展迭代很快,所以这些笔记内容也有类似新闻的时效性,不免有过时、或者错误的地方,欢迎指正 ^_^。
BEST
Lien(A.K.A 胡椒)